Hacking Go to give it sum types
I want sum types, so let's eschew all idiomatic Go code and best practices to hack the language and add them
I used to really like Go, but then I found languages with more advanced type systems and I found it kind of hard to go back.
Sometimes I do miss the readability of Go’s minimalistic syntax, and I think about what it would take for me to return.
One core thing that’s missing for me are sum types (or tagged unions). They’re my primary abstraction for expressing polymorphic data.
So I thought about how I could approximate them in Go.
In this post we’ll explore different ways of aproximating a contrived Pet sum type that can be a Cat, a Dog, or a Frog. Here’s what our variant types look like:
type Cat struct {
meowVolume int32
}
type Dog struct {
barkVolume int32
biteStrength int32
}
type Frog struct {
leapHeight int32
}
Attempt 1: Wrapper structλ
One idea is putting all our variants in one struct:type Pet struct {
cat *Cat
dog *Dog
frog *Frog
}
// We create it like this:
var pet Pet = Pet{cat: &Cat{meowVolume: 100}}
// Then we can use it like this:
func printPet(pet Pet) {
if pet.cat != nil {
fmt.Printf("Cat meow volume is: %d\n", pet.cat.meowVolume)
return
}
if pet.dog != nil {
fmt.Printf("Dog bark=%d bite=%d\n", pet.dog.barkVolume, pet.dog.biteStrength)
return
}
if pet.frog != nil {
fmt.Printf("Frog leap height is: %s\n", pet.frog.leapHeight)
return
}
panic("Uh oh!")
}
We simply use a non-nil pointer to indicate which variant of Pet the type is.
This kind of sucks becase now have to hold this implicit invariant that there can only be one non-nil pointer in our wrapper struct.
Also, we don’t have nice type-safety for all the if statements in printPet(). If we add another variant, we could easily forget its corresponding if statement.
Additionally, the Pet struct takes up 24 bytes (on 64-bit machines) because it needs to store 3 pointers.
If you’re into data-oriented design, a bunch of sirens may be going off in your head and while you are envisioning cache lines exploding. This is a lot of wasted space, especially because our largest variant is Dog which only takes up 8 bytes. That’s 3x larger than it needs to be!
Also, using pointers will heap allocate the Cat, Dog, or Frog which is an unnecessary expense.
Attempt 2: Interfacesλ
Polymorphism is usually achieved in Go through interfaces. We don’t have any generic functionality onPet, it just carries data specific to each pet variant, so we’ll give it a dummy function:
type PetInterface interface {
__isPet()
}
func (c Cat) __isPet() {}
func (d Dog) __isPet() {}
func (f Frog) __isPet() {}
func printPet(pet PetInterface) {
switch myValue := pet.(type) {
case Cat:
fmt.Printf("Cat meow volume is: %d\n", myValue.meowVolume)
return
case Dog:
fmt.Printf("Dog bark=%d bite=%d\n", myValue.barkVolume, myValue.biteStrength)
return
case Frog:
fmt.Printf("Frog leap height is: %d\n", myValue.leapHeight)
return
}
}
We get type-safety on the parameter of printPet, and type-safety switching on PetInterface.
However, interfaces have a couple performance drawbacks.
Interface methods typically incur a performance penalty due to dynamic dispatch, but if we switch/case on the interface it seems to mitigate that performance hit1 somewhat.
Additionally, interfaces typically require heap allocation of the underlying value2. This doesn’t matter if the value is heap allocated already, but if you have many small values this is a needless expense. Go’s compiler does perform escape analysis to allocate variables on the stack when possible, but this won’t for all cases3.
If I were a sane person I would stop here, this is an adequate solution. Obviously, it’s not as clean as languages with first-class sum type support, but it does the job pretty well.
But I’m not so I’m going to keep going down this rabbit hole.
Attempt 3: Let’s hack Goλ
I want more guarantees about when my data is heap allocated, and I like giving data the slimmest layout possible for cache-locality.Let’s go wild and do some weird stuff.
Fundamentally, a sum type / tagged union is just a tag + some data for the variant. Precisely, its just space for the tag and the largest variant size (so we can fit all variants).
So here’s the trick, Go has this unsafe.Pointer() function that lets you cast pointers like in C. We can make the data for the variants an array of bytes and cast it using unsafe.Pointer() depending on its tag.
One other thing we need to watch out for is alignment. We should add some padding to the tag to account for the alignment of the struct. For most CPUs, this is just a thing you need to do for the CPU to reduce the amount of read/write instructions, and on others CPUs unaligned accesses can cause exceptions or hardware faults.
Okay, let’s grab the size and alignment of each of our types:
fmt.Printf("Cat size=%d align=%d\n", unsafe.Sizeof(Cat{}), unsafe.Alignof(Cat{}))
fmt.Printf("Dog size=%d align=%d\n", unsafe.Sizeof(Dog{}), unsafe.Alignof(Dog{}))
fmt.Printf("Frog size=%d align=%d\n", unsafe.Sizeof(Frog{}), unsafe.Alignof(Frog{}))
Here’s what we get
Cat size=4 align=4
Dog size=8 align=4
Frog size=4 align=4
So our tag could be 1 byte, but we need to an additional 3 bytes so the data sits on a multiple of 4.
We also need to reserve 8 bytes so we have enough space for every variant.
This is what the struct layout looks like:
type Pet struct {
tag int32 // int32 is 4 bytes
data [8]uint8 // 8 bytes to fit the maximum variant (Dog)
}
And now we implement our previous printPet() function:
func printPet(pet Pet) {
switch pet.tag {
case 0:
cat := *(*Cat)(unsafe.Pointer(&pet.data))
fmt.Printf("Cat: %d\n", cat.meowVolume)
case 1:
dog := *(*Dog)(unsafe.Pointer(&pet.data))
fmt.Printf("Dog: %d %d\n", dog.barkVolume, dog.biteStrength)
case 2:
frog := *(*Frog)(unsafe.Pointer(&pet.data))
fmt.Printf("Frog: %d\n", frog.leapHeight)
}
}
There’s some weird stuff going on.
We have to use unsafe.Pointer(&pet.data) to cast a pointer to the data ([8]uint8) into a pointer to Cat, Dog, or Frog. Then we have to dereference it to actually get the value.
Ideally, you turn the whole pointer casting ordeal into helper functions:
func (p *Pet) asCat() *Cat {
if p.tag != 0 {
return nil
}
return (*Cat)(unsafe.Pointer(&p.data))
}
/* and the rest of them ... */
And some helper functions to create the Pet sumtype:
func newCat(cat Cat) Pet {
return Pet {
tag: 0,
data: *(*[8]uint8)(unsafe.Pointer(&cat)),
}
}
func newDog(dog Dog) Pet {
return Pet {
tag: 1,
data: *(*[8]uint8)(unsafe.Pointer(&dog)),
}
}
func newFrog(frog Frog) Pet {
return Pet {
tag: 2,
data: *(*[8]uint8)(unsafe.Pointer(&frog)),
}
}
Here’s an example of using it:
func main() {
var pet Pet = newCat(Cat{meowVolume: 420})
printPet(pet)
cat := pet.asCat()
cat.meowVolume = 69
fmt.Printf("Actual cat: %+v\n", cat)
// should be nil
dog := pet.asDog()
fmt.Printf("This should be nil: %+v\n", dog)
}
This approach has the slimmest representation (yay cache locality), and doesn’t require heap allocation so it should be faster.
However, we’ve compromised on ergonomics, type-safety, and the general safety of our entire program by using the unsafe package and potentially introducing undefined behavior4. Woo for over-engineering!
Benchmarksλ
We may have compromised on developer ergonomics and the general soundness of our program, but not on performance! Right…?I ran some benchmarks to verify this.
Here’s a gist of the code I benchmarked.
The Single tests create a single, random Pet and add its int32 fields up a bunch of times times.
The Array tests create many Pets and iterate through them and add their int32 fields up. This is where the implementations with the smaller memory layouts will perform better because more pets can fit in CPU cache.
Here are the results:
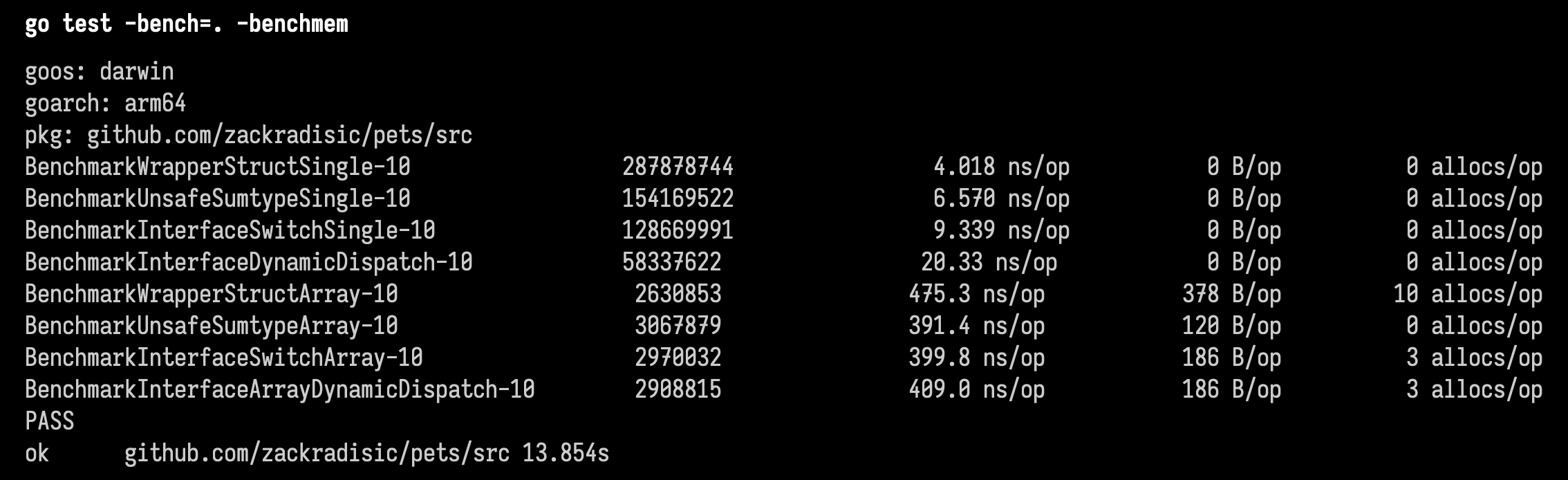
As expected, our unsafe sum type implementation is the fastest. But interestingly, only 2% faster than the interface approach using a type switch/case to eliminate dynamic dispatch.
Surprisingly, the wrapper struct implementation was faster than the sumtype implementation for the Single test. I’m not sure why, I suspect that Go is not able to optimize away all the weird unsafe pointer stuff I was doing so it was doing extra work.
And somehow, our unsafe sumtype implementation ended up taking the most amount of memory for the Array tests.
Conclusionλ
This is a terrible idea. It didn’t solve the problem of exhaustiveness. It kind of is better for performance in comaparison to attempt 1 or 2. The unsafe usage seems okay for this specific example, but won’t work nicely with GC if you for example store a pointer in one of the fields of one of the variants of the sum type (Go might GC the pointer since we cast it our data raw bytes so it won’t know if it should still be alive).Additionally, if you were insane enough to actually use this, you would have to generate this code for every sum type. If you had an Option<T> you would have to generate code for each T. I haven’t really played around with Go’s generics, maybe there is a way to do this with that.
Here’s the final code:
package main
import (
"fmt"
"unsafe"
)
type Cat struct {
meowVolume int32
}
type Dog struct {
barkVolume int32
biteStrength int32
}
type Frog struct {
leapHeight int32
}
type Pet struct {
tag int32 // int32 is 4 bytes
data [8]uint8 // 8 bytes to fit the maximum variant (Dog)
}
func printPet(pet Pet) {
switch pet.tag {
case 0:
cat := *(*Cat)(unsafe.Pointer(&pet.data))
fmt.Printf("Cat: %d\n", cat.meowVolume)
case 1:
dog := *(*Dog)(unsafe.Pointer(&pet.data))
fmt.Printf("Dog: %d %d\n", dog.barkVolume, dog.biteStrength)
case 2:
frog := *(*Frog)(unsafe.Pointer(&pet.data))
fmt.Printf("Frog: %d\n", frog.leapHeight)
}
}
func (p *Pet) asCat() *Cat {
if p.tag != 0 {
return nil
}
return (*Cat)(unsafe.Pointer(&p.data))
}
func (p *Pet) asDog() *Dog {
if p.tag != 1 {
return nil
}
return (*Dog)(unsafe.Pointer(&p.data))
}
func (p *Pet) asFrog() *Frog {
if p.tag != 2 {
return nil
}
return (*Frog)(unsafe.Pointer(&p.data))
}
func newCat(cat Cat) Pet {
return Pet {
tag: 0,
data: *(*[8]uint8)(unsafe.Pointer(&cat)),
}
}
func newDog(dog Dog) Pet {
return Pet {
tag: 1,
data: *(*[8]uint8)(unsafe.Pointer(&dog)),
}
}
func newFrog(frog Frog) Pet {
return Pet {
tag: 2,
data: *(*[8]uint8)(unsafe.Pointer(&frog)),
}
}
func main() {
var pet Pet = newCat(Cat{meowVolume: 420})
printPet(pet)
cat := pet.asCat()
cat.meowVolume = 69
fmt.Printf("Actual cat: %+v\n", cat)
dog := pet.asDog()
fmt.Printf("Actual dog: %+v\n", dog)
}
Footnotesλ
If you use interfaces the idiomatic Go way, you most likely will suffer a performance penalty from dynamic dispatch (here for more on dynamic dispatch + interfaces). It looks like this:
type Pet interface {
printPet()
}
func (c Cat) printPet() {
fmt.Printf("Cat meow volume is: %d\n", c.meowVolume)
}
/* and the rest... */
But if we switch/case on PetInterface like in the code sample for attempt 1:
func printPet(pet PetInterface) {
switch value := pet.(type) {
case Cat:
fmt.Printf("Cat meow volume is: %d\n", value.meowVolume)
/* and the rest .. */
}
}
Go seems to be able to optimize away the dynamic dispatch somewhat. From benchmarking, I saw that the dynamic dispatch version was ~2.22x slower!
You can read about this in detail at this link. Here’s a TLDR:
The Go runtime’s internal representation of an interface looks like this:
type iface struct { // 16 bytes on a 64bit arch
tab *itab
data unsafe.Pointer
}
The tab field points to an itab structure which just contains some details about the type of the interface and the type it points to.
The data field is a raw pointer to the underlying value of the interface.
Typically, this means the underlying value of the interface needs to be heap allocated, though the Go compiler make optimizations and deliberately avoid this in certain cases..
You can run/compile go code with the -gcflags "m" command line arguments to see compiler log the escape analysis in action.
In this example, escape analysis determines that cat can stay on the stack:
func main() {
cat := Cat{meowVolume: 0}
printPet(cat)
}
func printPet(pet PetInterface) {
switch myValue := pet.(type) {
case Cat:
fmt.Printf("Cat meow volume is: %d\n", myValue.meowVolume)
return
case Dog:
fmt.Printf("Dog bark=%d bite=%d\n", myValue.barkVolume, myValue.biteStrength)
return
case Frog:
fmt.Printf("Frog leap height is: %d\n", myValue.leapHeight)
return
}
}
❯ go run -gcflags "-m" main.go
# command-line-arguments
./main.go:22:6: can inline Cat.__isPet
./main.go:23:6: can inline Dog.__isPet
./main.go:24:6: can inline Frog.__isPet
./main.go:34:13: inlining call to fmt.Printf
./main.go:37:13: inlining call to fmt.Printf
./main.go:40:13: inlining call to fmt.Printf
./main.go:26:6: can inline main
<autogenerated>:1: inlining call to Cat.__isPet
<autogenerated>:1: inlining call to Dog.__isPet
<autogenerated>:1: inlining call to Frog.__isPet
./main.go:31:15: pet does not escape
./main.go:34:13: ... argument does not escape
./main.go:34:49: myValue.meowVolume escapes to heap
./main.go:37:13: ... argument does not escape
./main.go:37:46: myValue.barkVolume escapes to heap
./main.go:37:66: myValue.biteStrength escapes to heap
./main.go:40:13: ... argument does not escape
./main.go:40:50: myValue.leapHeight escapes to heap
./main.go:28:14: cat does not escape
Cat meow volume is: 0
One example is that this implementation could cause a memory leak if any of the variants have a field that stores a pointer or some heap allocated object like an interface.